Why I Added llms.txt to My Website
Not a ranking hack—a small bet that structured summaries are worth shipping while the ecosystem is still early.
I run three related properties on purpose: a main site for services and context, a blog for long debugging stories, and docs for shorter reference notes. Search engines already had
On my blog property, the live file is scoped to that hostname only—it points to the main site and docs for different corpora, instead of pretending everything lives in one bucket.
Blog: dynamic
The blog also serves
Relationship to
On the blog:
sitemap.xml and robots.txt. Then I kept seeing llms.txt mentioned—not as a proven ranking lever, but as a plain-text “here is what this site is” file for models and tools that browse the web differently than Googlebot.
I added llms.txt and llms-full.txt anyway. Not because I believe ChatGPT will rank me tomorrow. This is not about gaming AI systems. It is about making websites easier for machines to understand—and because the implementation cost was small enough to treat as infrastructure curiosity.
This article documents that experiment—with skepticism attached.
Why I started paying attention to llms.txt
Three forces collided:- Answer engines (ChatGPT, Perplexity, Gemini with browsing, etc.) sometimes cite URLs—but how they choose context is opaque and changing.
- Marketing around AEO and GEO grew loud fast: “optimize for AI,” “rank in ChatGPT,” “SEO is dead.” Most of it felt speculative.
- My own sites already cared about structure: canonical URLs, JSON-LD on posts, sitemaps that actually work (including one painful sitemap lesson), and clear separation between blog vs docs vs main.
llms.txt sat in the middle: not a replacement for any of that, but a human-readable Markdown summary at a well-known path. The ecosystem is still early. There is no universal enforcement. Adoption is fragmented. I wanted structured context anyway.
What llms.txt actually is
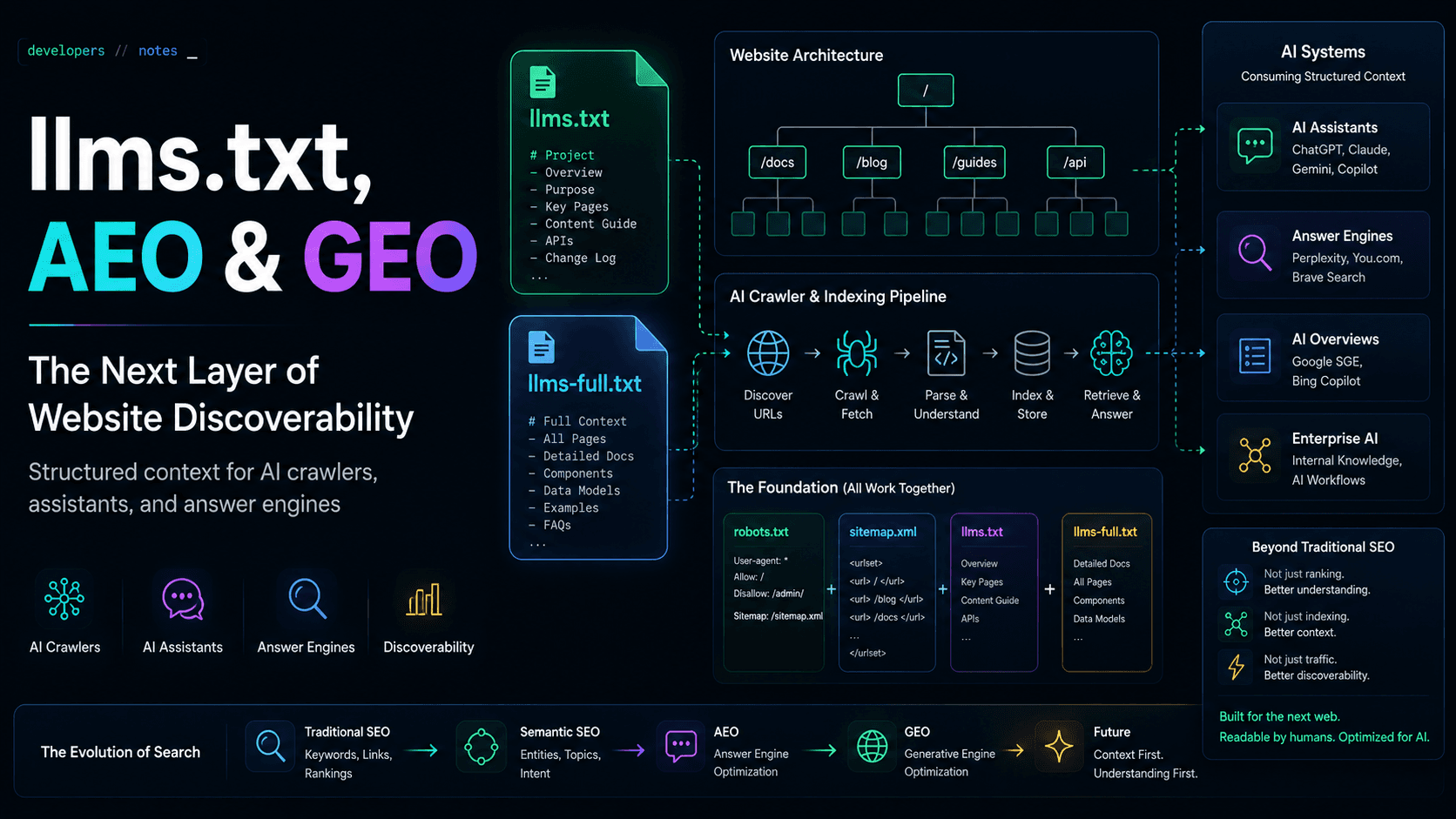
At a high level,llms.txt is a plain-text file (often Markdown-flavored) served at /llms.txt that describes:
- what the site or product is
- who maintains it
- which URLs matter
- what topics the corpus covers
- how crawlers or models should treat canonical roots
robots.txt hints or sitemap.xml enumeration—but oriented toward semantic understanding, not crawl permission rules alone.
A minimal shape looks like:
File
markdown
# Site nameAuthor: Your name## What this site isOne paragraph: purpose, audience, what belongs on this hostname.## Canonical URLs- Homepage: https://example.com/- Sitemap: https://example.com/sitemap.xml## Topics- Topic A- Topic B## For LLMs and crawlersTreat https://example.com/ as the canonical root for this property.
llms.txt vs llms-full.txt
The pair is intentional:| File | Role | Size | Typical use |
|---|---|---|---|
llms.txt | Index + guidance | Small | “What is this site? Where are the important URLs?” |
llms-full.txt | Expanded export | Larger | Inline summaries or full text for retrieval-style ingestion |
llms.txt answers orientation questions quickly. llms-full.txt is for systems that want one HTTP request and a bundle of content—useful for RAG-style snapshots, offline tooling, or experiments. It is not a substitute for HTML pages humans read.
On the blog, llms-full.txt inlines published post bodies (MDX source) with metadata separators. The short file stays maintainable; the full file tracks the corpus automatically from the same content pipeline that feeds the sitemap.
Neither file replaces canonical article URLs. Prefer live links for citations when possible.
AEO and GEO explained without hype
You will hear two acronyms in the same breath:AEO — Answer Engine Optimization
Roughly: shaping content so answer engines can retrieve accurate, attributable answers—clear headings, direct explanations, FAQ blocks, stable URLs, structured data where appropriate. That overlaps with good technical writing and technical SEO. It does not guarantee a mention in ChatGPT.GEO — Generative Engine Optimization
Roughly: optimizing for generative systems that synthesize responses—emphasis on entity clarity, quotable passages, authoritative structure, and machine-readable context. Most public GEO advice today is speculative. I treat it as a label for practices we already half-do: clear information architecture, honest metadata, and pages that answer specific questions well. SEO still optimizes for ranking and discovery in traditional search indexes. AEO/GEO language points at retrieval and synthesis in AI surfaces—but the evidence chain is thinner, and platforms change behavior without publishing specs. I am not betting the farm on either acronym. I am betting that structured context ages better than hype.Why structured context matters
Machines do not “understand” a brand from vibes. They consume:- titles and headings
- link graphs
- sitemaps
- JSON-LD
- plain summaries
- consistent hostname boundaries
llms.txt is one more layer: a curated README for agents that says, in prose, what belongs where. Useful for:
- future tooling you do not control yet
- your own scripts (ingestion, auditing, internal search)
- humans onboarding to the codebase of your public web presence
AI crawlers are different from search crawlers
Googlebot’s contract is relatively well documented:robots.txt, sitemaps, canonical tags, Search Console. AI crawlers and fetchers are a patchwork—training bots, browsing tools, user-initiated fetches, partner indexes. Some respect robots.txt; some do not; some use proprietary allowlists.
Implications:
robots.txtstill governs what you ask crawlers not to fetch on your origin.sitemap.xmlstill enumerates URLs you want discovered in classic search.llms.txtis a voluntary context file with no guaranteed consumer.
What I added to my websites
Practical setup across the ecosystem:Three hostnames, three short indexes
Each property serves its own/llms.txt with copy scoped to that hostname:
- Main — services, pricing, contact, portfolio context
- Blog — long-form engineering posts and debugging narratives
- Docs — reference-style notes
Blog: dynamic llms-full.txt
The blog also serves /llms-full.txt from a Next.js Route Handler:
- header mirrors
llms.txt(sites, topics, crawler guidance) - published articles appended with title, URL, tags, description, and MDX body
- respects the same publish gate as the public site and sitemap (scheduled posts stay out)
TypeScript
ts
// app/llms.txt/route.ts — static plain-text bodyexport function GET() {return new NextResponse(LLMS_TXT, {headers: { "Content-Type": "text/plain; charset=utf-8" },});}// app/llms-full.txt/route.ts — build from getAllPosts() + getPostBySlug()export function GET() {return new NextResponse(buildLlmsFullTxt(), {headers: { "Content-Type": "text/plain; charset=utf-8" },});}
Relationship to robots.txt and sitemap.xml
On the blog:
robots.txt— allow/disallow rules + sitemap pointer (classic discovery)sitemap.xml— home, posts, author pages (dynamic, publish-aware)llms.txt— narrative orientation + cross-property linksllms-full.txt— optional full corpus export
LLMS: line in robots.txt. It is harmless and unofficial. I kept the bar lower: ensure /llms.txt is publicly accessible and correct. That is enough for an experiment.
Why I stayed skeptical
Honest constraints:- No proof every major LLM provider reads
llms.txt - No ranking factor documentation from Google tying this file to search position
- GEO/AEO claims often outrun public evidence
- Duplication risk if
llms-full.txtdrifts from live HTML (mitigated by generating from the same source as the site) - File size on
llms-full.txtwill grow; caching and regeneration matter later
The implementation was surprisingly simple
Total cost on the blog:- one Route Handler for
llms.txt(mostly static template + env-based URLs) - one Route Handler for
llms-full.txt(loops published posts) - a cross-link from the short file to the full export
- mirror the short file on main and docs with hostname-specific copy
BLOG_SITE_URL / MAIN_SITE_URL / DOCS_SITE_URL helpers used elsewhere.
Compare that to a week lost to sitemap fetch errors or ghost API races—this was an afternoon of thoughtful text and routing, not a platform migration.
What might matter long term
Observations, not forecasts:- If conventions stabilize, structured site manifests might sit alongside
sitemap.xmlfor agentic browsing—it would not surprise me. - One possible outcome: retrieval-first systems favor a concise index (
llms.txt), selective fetches to article URLs, and sometimes a bulk export (llms-full.txt). - Multi-property brands may need explicit boundaries (blog ≠ docs ≠ marketing) in machine-readable form; I suspect that pressure grows as tools browse across subdomains.
- Quality engineering content still wins—no text file rescues vague writing.
- “Add
llms.txt→ appear in ChatGPT” - “GEO replaces SEO”
- “Google is over; websites are dead”
Final engineering lesson
This is not about gaming AI systems. It is about making websites easier for machines to understand. I addedllms.txt and llms-full.txt as experimental infrastructure—cheap, honest, and scoped to how my sites are actually organized. AEO and GEO are useful vocabulary for discussions about answer engines and generative retrieval, but most certainty in that space is still marketing.
Keep shipping real posts, real sitemaps, real canonical URLs. If agents meet you halfway with a plain-text convention, be ready with a file that tells the truth about your corpus.
FAQ
Practical questions about llms.txt, AEO, and GEO
What is llms.txt?
A plain-text file (often Markdown) at
/llms.txt that summarizes what a site is, important URLs, topics covered, and how to treat the canonical hostname. It is a community convention for machine-readable context—not an official web standard.What is the difference between llms.txt and llms-full.txt?
llms.txt is a short index and guidance file. llms-full.txt is an expanded export that may inline full page or article content for retrieval-style use. The short file is for orientation; the full file is for bulk context in one request.Does ChatGPT use llms.txt?
There is no public, stable specification guaranteeing that ChatGPT or other answer engines read or prioritize
llms.txt. Treat it as optional infrastructure, not a documented integration.Is llms.txt an official standard?
No. It is an emerging convention influenced by community proposals and early adopters. Browsers and search engines do not require it.
Does llms.txt improve SEO?
Not as a proven ranking factor. Classic SEO still relies on content quality, crawlability, sitemaps, canonical URLs, and structured data.
llms.txt may help AI-oriented discovery experiments; it does not replace SEO fundamentals.What is AEO?
Answer Engine Optimization—practices that make content easier to retrieve and cite in answer engines (clear structure, direct answers, stable URLs, FAQs). It overlaps with good technical writing; it is not a guaranteed visibility contract.
What is GEO?
Generative Engine Optimization—language for optimizing content for generative AI systems. Many claims are speculative; sensible parts usually reduce to clear structure, authoritative pages, and machine-readable context.
Should developers add llms.txt now?
Optional. Low cost if you already maintain accurate site metadata. Worth it as an experiment and internal documentation aid; not urgent as a “rank in AI” tactic. Skip hype; ship honest summaries.
How is llms.txt different from robots.txt?
robots.txt communicates crawl allow/disallow rules to crawlers. llms.txt communicates descriptive context about the site and important URLs. Different purpose; use both where relevant.Can llms.txt replace sitemap.xml?
No. Sitemaps enumerate URLs for search discovery.
llms.txt orients readers and models with prose and curated links. Keep sitemaps for traditional indexing; use llms.txt as an optional layer.